
Our Heuristics to Spot AI-Generated Content are Useless
Save yourself the trouble and just flip a coin

I used to hate spelling mistakes.
A few years ago, I received a pamphlet from an elementary school advertising its first grade to us prospective parents, and before even reading the few words on it, I spotted a typo. And I just couldn’t shake it off. I didn’t want to judge—everyone can make mistakes—but I couldn’t wrap my head around it. In my mind, it created an immediate internal conflict: how could they teach my child to spell if they hadn’t caught a typo on a document printed by the hundreds? I pictured the person responsible for putting the pamphlet together, making a mistake, and neglectfully leaving it there.
I didn’t like them.
Today, I am different. I still spot typos and grammatical mistakes from a mile away, but now my mind finds comfort in them. Now, that mistake is a signal: it tells me a human being—maybe tired, busy, and earnest—sat down and typed those words.
And I sympathize with them. How the tables have turned!
I used to see a typo as a sign of neglect. In the age of AI, I see it as a sign of human presence.
I had to dig deeper to find validation for my feelings. I eventually found it across three different papers, starting with a study1 on an experiment we’ve all seen and done, even here on Substack: can you spot the AI-written text? The answer, as we all know by now, is a general “no.” We can’t. This first study shows that ordinary people guessing between AI-generated and human-authored bios (short self-introductions, like on Airbnb, job applications, and online dating) are only as effective as making a random choice. So why am I referencing this paper if the results are exactly as expected?
Because it gets me closer to my goal: understanding our perception (and the evolution of this perception) of grammatical errors. While the participants couldn’t accurately distinguish between AI and human-written bios, they were in pretty good agreement with each other about which ones they thought were AI. This wasn’t because they discussed their ideas; it was because they relied on the same cues—or heuristics—to make their choices. Too bad these common cues are exactly what deceive them.
Grammatical issues, for example, were on their list of evidence for AI writers. However, the researchers showed the opposite: these were actually more common in the humans’ writings. It seems that at the time of the experiment, people still attributed bad grammar to AI. The same held true for long words and rare word combinations. Some other cues the participants relied on were not indicative of AI or humans either—such as the use of first-person pronouns, focusing on the past, or family words—yet they perceived them as signs of a human writer. They would have performed much better by relying on cues that are actually functional for detecting an AI writer, like nonsensical or repetitive content.
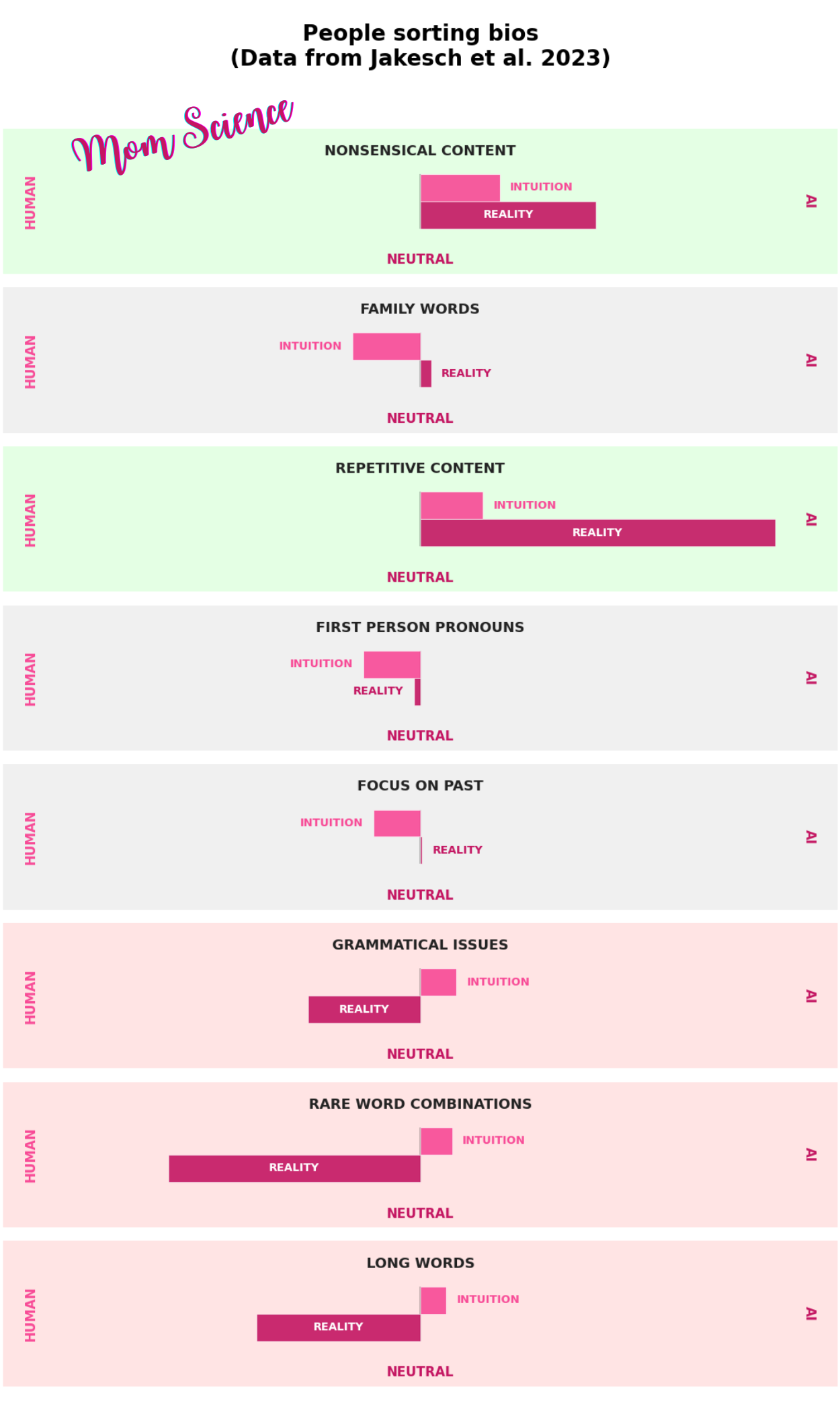
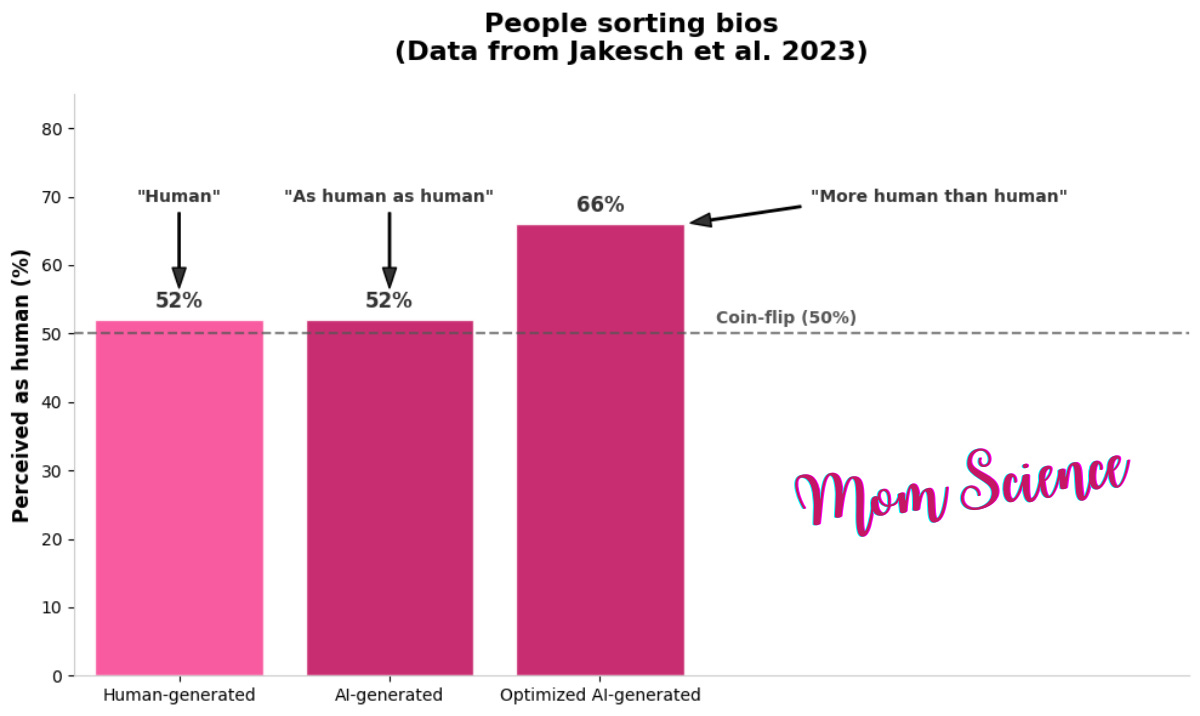
After gathering this knowledge on what heuristics people relied on in order to make a decision, the researchers validated their findings by showing that AI writers can appear “more human than humans” if given these guidelines. When prompted to mislead by paying attention to these cues, their texts were chosen as human-written with about 66% probability—compared to the actual human ones with about 52%. Menacing, isn’t it?
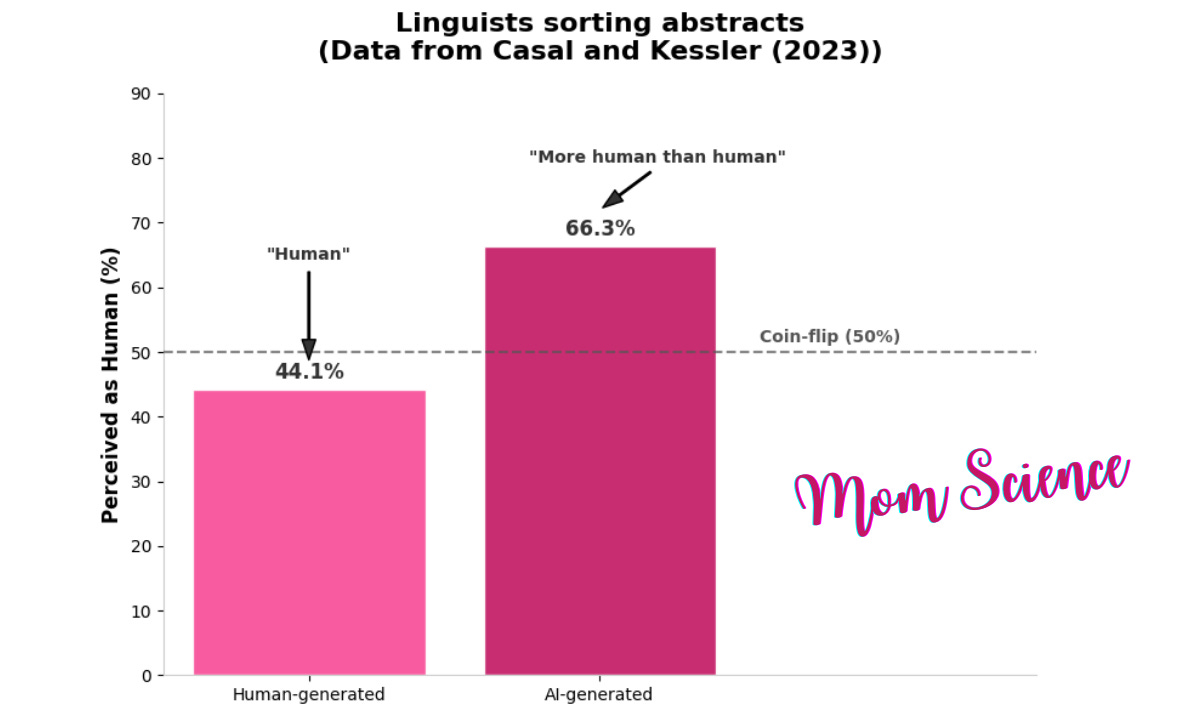
Looking at the results, you could feel that there must be people who are superior at spotting AI-generated texts. And who would be better than frequent reviewers from the top linguistic journals? In another study2, these highly qualified professionals were asked to decide whether abstracts (the summaries at the beginning of scientific papers) were written by humans or AI. And they failed miserably. They performed so poorly that they would have done better flipping most of their answers: their accuracy in choosing AI or human was on average 38.9%. They were a little better at identifying a human-written text as human-written, with a success rate of 44.1%; for AI, the rate of identification was only 33.7%. This is way below the 50% accuracy of a coin toss. As I read the results, I was equally surprised and panicked by how helpless we are, but on second thought, I think the reviewers were given an incredibly hard task with this one.
AI’s ability is not the same in all areas of writing. Writing computer code is certainly easy for an AI. Writing a heartfelt poem is, I would say, way more difficult. If I were to ask an AI to write this Substack post for me by briefly explaining the concept, the topic, and how I want it to rely on scientific studies—while also being conversational and casual—my prediction is that it would turn out pretty bad. While it theoretically could do it, how much credit would you give that it could write a comprehensive text that relies on real data without hallucinations? I definitely wouldn’t bet my money on it.
Research abstracts, however, are probably one of the most suitable tasks for AI. Why? When it comes to writing an abstract, there is a fully written paper to summarize. The facts are there; there is no need to extrapolate anything. Indeed, there shouldn’t be anything in an abstract that isn’t in the paper itself. There is no room to hallucinate, no citations to include, and the words to use are already there in the long document. The only job is to choose which ones to include and put them together into a representative little paragraph. A good portion (about 37%) of editors who were asked during the same study about their opinion on researchers’ ethical use of AI agreed that writing the abstract is included. All in all, I think we shouldn’t be surprised that distinguishing between AI and human-written abstracts is not even worth trying.
Other than the overall success, the cues the linguists relied on—and how they mostly failed to help them—are fascinating in itself. While only seven of the participants were involved in the discussion of the cues, they were in pretty good accordance with each other about the top four.
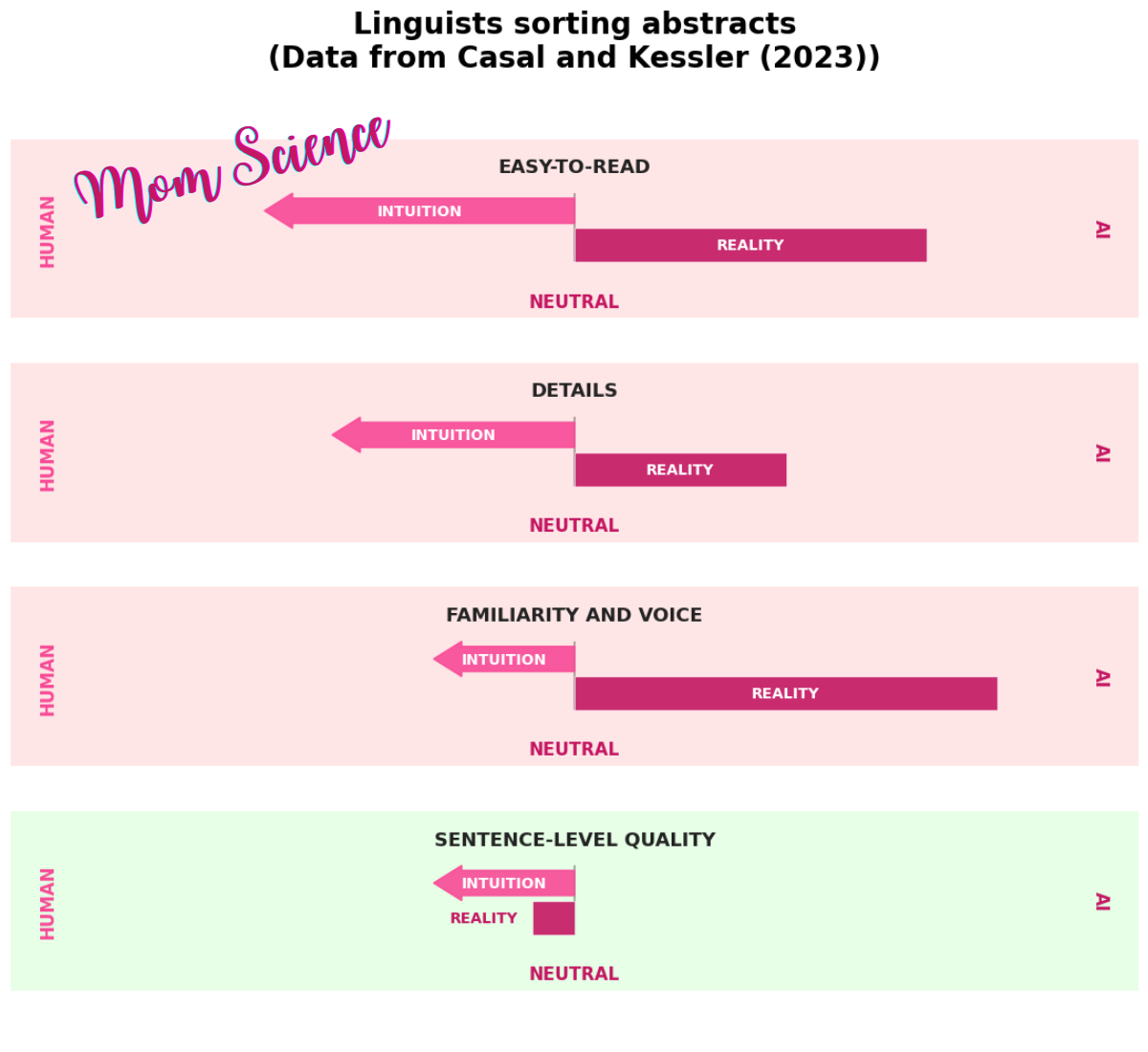
The first one was basically how easy-to-read the abstract is: the easier to read, the more likely it was human-written, according to them. But they were wrong. Reviewers who based their decision on this had a 22.2% rate in correct identification.
The second was the inclusion of details vs vagueness. You guessed right: detail was attributed to humans, vagueness to AI. This cue helped them reach a correct conclusion in 28.6% of the abstracts where this criterion was applied by a reviewer.
Third was familiarity and voice—if there is a unique voice, it must be human, right? Turns out, no. This criterion led to a 20% success rate.
The fourth is the one I would call the functional cue out of the four, which is writing quality on a sentence level. Not the same as grammatical error, but how well-constructed sentences were: if it’s good, they assumed human, otherwise AI. This cue led to 60% correct identification, which is way better than the previous ones.
Do you see a pattern with these top four cues and how they were interpreted? In all cases, the positive side was attributed to humans, the negative to AI. The reviewers were obviously feeling that human writing is superior, and this assumption led them to make some pretty bad choices.
You might find it interesting that the linguists never looked for grammatical errors in the abstracts, but I believe that this is a side effect of the choice of the texts. Human-written or not, abstracts are short and very important for any paper, so I doubt that any human would leave errors in them. My guess is that all of them were free of typos and errors.
To get a more recent view of how the focus has shifted from blaming AI for making grammatical errors, I read a study3 where university professors were asked about the cues they rely on to determine if students’ essays were written by AI. No classification test was involved this time; they just discussed and rated the features they use to make a decision. Their top four cues attributed to AI were hallucinated facts and hallucinated sources, and as you could guess, the absence of language errors. The fourth was repetition. I agree that hallucinated facts really are tell-tale signs of AI since students rarely make up non-existent journals or papers, and professors have a way of validating facts and sources. However, the presence of errors shifting from an AI attribution to a human one doesn’t seem like a very stable cue.
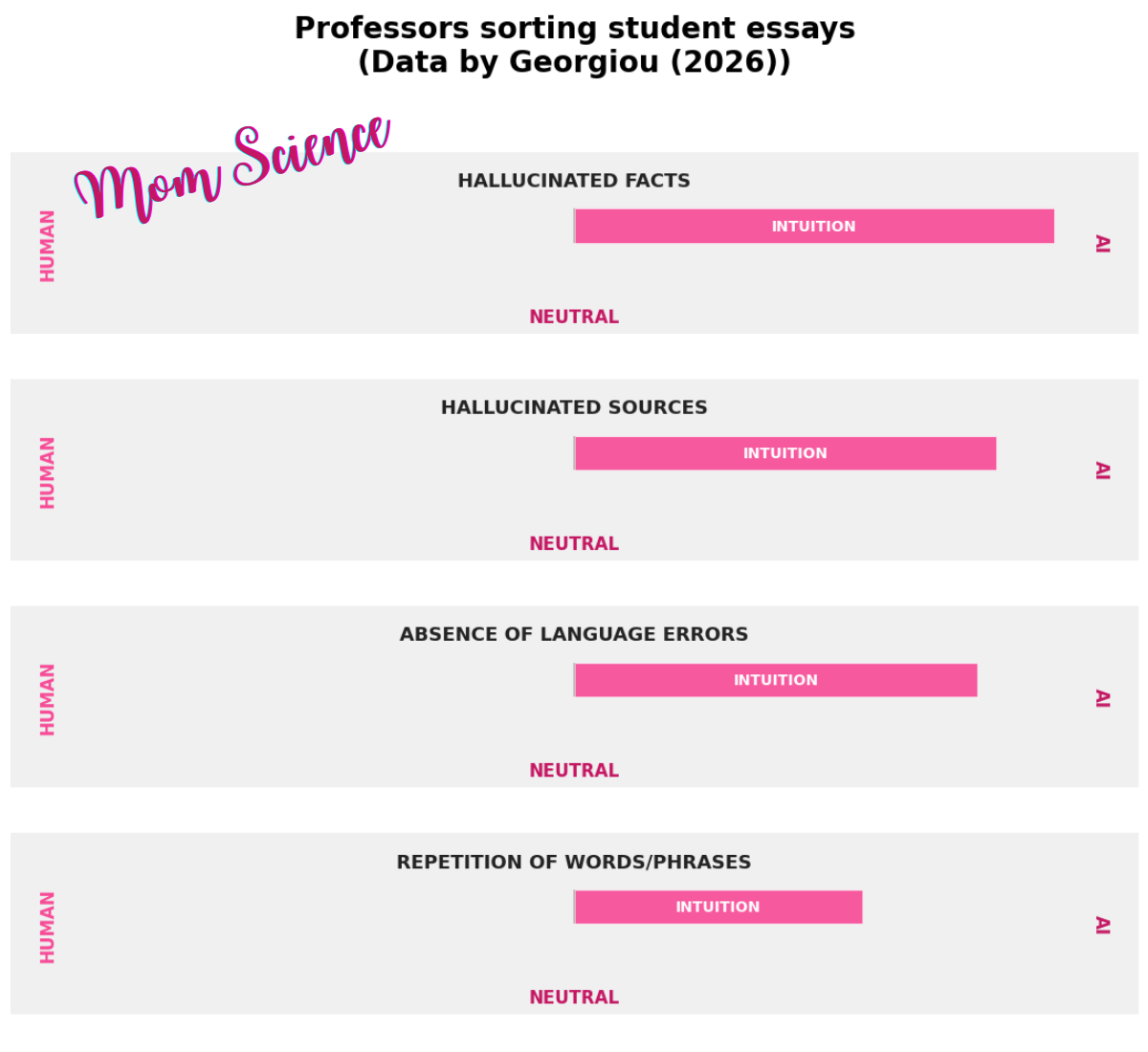
I have certainly caught myself wondering if the email—or Substack note, for that matter—that I’ve personally written will be assumed to be AI-generated. I haven’t gone as far as adding mistakes to appear more human, but I have made it less "suspicious-looking" by switching from an em-dash to a colon, for example. I find it odd that the research I’m discussing can be used for the wrong reasons: these results, when plugged into an AI, can help it adapt to form a next level of deception. I wonder if errors—which have already had a journey from being a sign of mediocre AI to one of humanity—will fall into a vicious cycle. Maybe AI will routinely include them in its output to avoid detection, tilting the scale back to "typo means AI," before correcting again. Who knows?
Looking at all these studies—the scores and the cues the participants attributed to either AI or human authors—I think the most important conclusion is that we simply can’t do it. We are not able to reliably tell who wrote the text. The only cues that seem to work are nonsensical, hallucinated, or repetitive content. However, these are only relevant for certain kinds of texts. Summaries seem to be a very difficult genre, while citations and facts of essays might offer a chance to spot AI if they are made up and clearly hallucinated.
This raises an interesting follow-up question: if spotting AI use is so hard, is it even worth disclosing, or are people better off covering their tracks? While I believe that honesty and transparency are the way to go, the debate is much more nuanced due to the loss of trust and the still very real rejection of AI-generated or AI-aided content. Having read some papers on this question, I’m fairly certain that this will be the topic of another post!
Jakesch, M., Hancock, J. T., & Naaman, M. (2023). Human heuristics for AI-generated language are flawed. Proceedings of the National Academy of Sciences (PNAS), 120(11), e2208839120. https://doi.org/10.1073/pnas.2208839120
Casal, J. E., & Kessler, M. (2023). Can linguists distinguish between ChatGPT/AI and human writing? A study of research ethics and academic publishing. Research Methods in Applied Linguistics, 2(3), 100068. https://doi.org/10.1016/j.rmal.2023.100068
Georgiou, G. P. (2026). Key Features to Distinguish Between Human- and AI-Generated Texts: Perspectives from University Professors. AI in Education, 2(1), 2. https://doi.org/10.3390/aieduc2010002