
Mommy Trained a Neural Network
If we all know that calling ourselves Mommy is annoying, why are we doing it?

TL;DR: I am more likely to say “Mommy’s here” to my upset baby than “I’m here”, and probably so are you. This is either one of those magical maternal instincts that help the baby thrive and learn the language, or an annoying habit that slows the process down. A study concluded that this habit — paired up with a similar one where we say to the child sentences like “Is the baby hungry?” instead of “Are you hungry?” — aids the learning process of the pronouns “I” and “you”. The issue is that this conclusion is based only on eleven children, so take it with a grain of salt. However, I ran my own simulation to challenge the claim, and it backed up the positive effect!

If I say a word too many times in a row, the meaning starts to slip, and I start to doubt if it even means what I thought it did.
From time to time, I have a similar experience with habits. They come naturally and happen all the time, but giving them some thought, they make little sense. Like talking to my children and referring to myself as Mommy, or referring to them by their name or the term “baby”. I have (or had, prior to writing this post) no particular reason to use these absolute labels instead of the usual relative pronouns when I talk to my kids. I also remember listening to a podcaster before I even had kids claiming she was set not to refer to herself as Mommy to her children, yet she still catches herself doing it. This seems to be an instinct on our side. But is it a good one? I had to dig deeper into the topic, and it led me to a surprising direction: finally learning up close what a neural network is and how to train one.
Like most parenting topics, we hear pros and cons all the time – I certainly have been told by well-wishers to just speak to the child as if I were talking to an adult. As it turns out, even professionals have disagreed about it. One side worried that mixing “I” with “Mommy” and “you” with the child’s name would only confuse children (some even called it deviant speech) and just give them a faulty pattern they later have to unlearn. Meanwhile, the other side thought these absolute labels help children notice who occupies each role in a conversation. Some even suggest that those children who have a phase of calling themselves by their name instead of “I” are making up for the fact that their parents rarely do so. Fascinating, isn’t it?
True to the premise of MomScience, I decided to look into the science behind parents using absolute labels — referring to themselves by a kin term such as “Mommy” or using the actual name for themselves or the child instead of “I” or “you” — and share the findings with you.
I found the perfectly fitting scientific study! Or did I?
In 2011, Smiley, Chang, and Allhoff published a paper1 on how these absolute labels in parental input affect children’s language development. Naturally, since “Mommy”, “Tommy”, or “baby” are alternatives to “I” and “you”, this phenomenon is intertwined with the mastery of first- and second-person pronouns.
Children have their work cut out for them with learning to speak, and one cornerstone that is really hard for them is pronouns. I never gave this much thought, but it is quite straightforward why: elephant always means elephant, table is table, but “I” is all over the place. Kids hear everyone use it, and “I” doesn’t always refer to the same person. Nor does “you”. It is one thing for them to understand people talking to them using these annoyingly shifting pronouns, but can you imagine having to adapt to them by the time they start talking? They have to start using “I” to refer to themselves in a world where no one has ever referred to them as “I”. It’s quite amazing that they manage to do that.
Let’s see the connection between absolute labels and pronoun mastery!
The Smiley study analyzed the linguistic environment and the pronoun learning process of eleven first-born children. They found that children whose parents provided anchors for the pronouns “I” and “you” by using absolute labels often as alternatives (like “Mommy” for “I” and “baby” for “you”) learned the pronouns “I” and “you” more quickly and with fewer alternate forms of self-reference, such as calling themselves by their proper name.
I hate to be the bad guy here, but I must alert you about a small yet crucial detail.
Eleven children are not a broad sample, and even among them, the group where parents provided plenty of absolute labels in both directions had only two children. So they base their conclusion on these two kids. Moreover, all the children being first-born is a strong restriction.
So now what? We have the study we were looking for, the reassuring conclusion, but we would be overly confident to accept it at face value due to the small sample size. Maybe those two kids just happened to be the smartest or most talented of the eleven children, and the parental input had nothing to do with their mastery of pronouns.
How do I add any certainty to the question without conducting a larger study on my own?
There might be a feasible way.
The Smiley study mentions an earlier scientific paper that caught my attention. Yes, I read plenty of papers about interesting experiments testing children’s pronoun understanding and usage, but this is not one of those. Instead of working with children and trying to uncover where they are in their journey to pronoun acquisition, the authors chose a completely different path: a computer simulation. Which is something I could potentially do myself without organizing any real-life study!
The OG Simulation Study
The simulation study2 was published in 1999 by Oshima-Takane, Takane, and Shultz about the ideal circumstance for children to master first- and second-person pronouns. They didn’t consider absolute labels, just examined the linguistic environment in terms of the balance between child-directed and overheard speech, and how many people were involved.
Why? Because the hardship with pronouns is that they are all over the place, and children need good training data to understand them.
Confusingly, Mommy can be “I” when she is talking about herself, but when Daddy talks to her, she is “you”. But “you” is the baby when Mommy is addressing them. So, who is the baby when they want to ask for a glass of water for the very first time? Should they say “you are thirsty”, since Mommy always calls them “you”? Or can they make the leap of thought to say “I am thirsty”, because whenever someone talks about themselves, they use the pronoun “I”? According to the study, what the child settles on depends on the circumstances and their phase in the learning process.
Imagine the edge case when a baby is always alone with their mom. Mom talks to the child often, but every sentence is always addressed to the baby. So the child only hears Mom saying “I” when referring to herself and “you” when referring to the child. The issue is obvious: the child has no reason to doubt that “you” is just another name for themselves, and so is “I” for Mom.
On the contrary, a child who hears their parents talking to one another experiences the shift of you and I all the time. Even though the child is never referred to as “I”, they see that both Mom and Dad use it to talk about themselves, at least giving the child a chance to adapt the correct pronoun when it is their turn to talk.
Oshima-Takane and her colleagues trained a neural network. I know, we are not surprised to see neural networks. They are a hot topic these days, but have you seen them being used before the millennium? I sure haven’t. Maybe because by then I was a child myself, but you do see the point.
They made a model of the linguistic environment surrounding the child when they are learning to speak, gave this input to their neural network, and analyzed how effectively this model learned to produce first- and second-person pronouns. The paper presented multiple simulations and multiple stages of learning, here I will just focus on what is relevant for our own journey.
In a five-person setup, the authors showed an interesting pattern: if the input was only speech directed to the child, it was not enough for the model to master the pronoun use. However, starting from 20% overheard speech, the neural network was indeed able to produce correct first- and second-person pronouns as soon as it was asked to “speak”.
Remember here that the task is not easy: the system has to learn how to speak from training data where it was never in the speaker role.
The Technical Details and Reproduction of the OG Simulation — You can Skip This
Before jumping into my own neural network training for absolute labels, I first tried to rerun the simulation that I just described to see if, using Codex, I could implement a close enough model on my own.
The particular type of neural network that they used is called a Cascade-Correlation (CC) model. Their choice is deliberate, as this model had been proven successful in modeling the cognitive learning processes of children in mastering physical rules or ordered relations, such as bigger/smaller, for example. Indeed, this is a special neural network where the structure and the size of the network is not pre-given; it adapts to the task during training. If it needs more neurons, it adds them, but if a smaller number will do, it stays small and efficient.
The “Cascade” part of the name means that instead of dumping new neurons into a single flat layer, the network stacks them consecutively like a waterfall, with each new hidden unit receiving inputs from all previous ones. The “Correlation” part reflects how a new neuron is selected: before being added, it is explicitly trained to maximize the correlation between its own activation and the residual error the network is still making. Once it is inserted into the architecture, its incoming weights are permanently frozen, turning it into a stable, permanent feature detector.
The idea is that this structure mirrors how children learn.
Setting up a CC model (not the same CC model), I got the following results in terms of pronoun mastery and learning speed, given the different child-directed and overheard speech proportions:
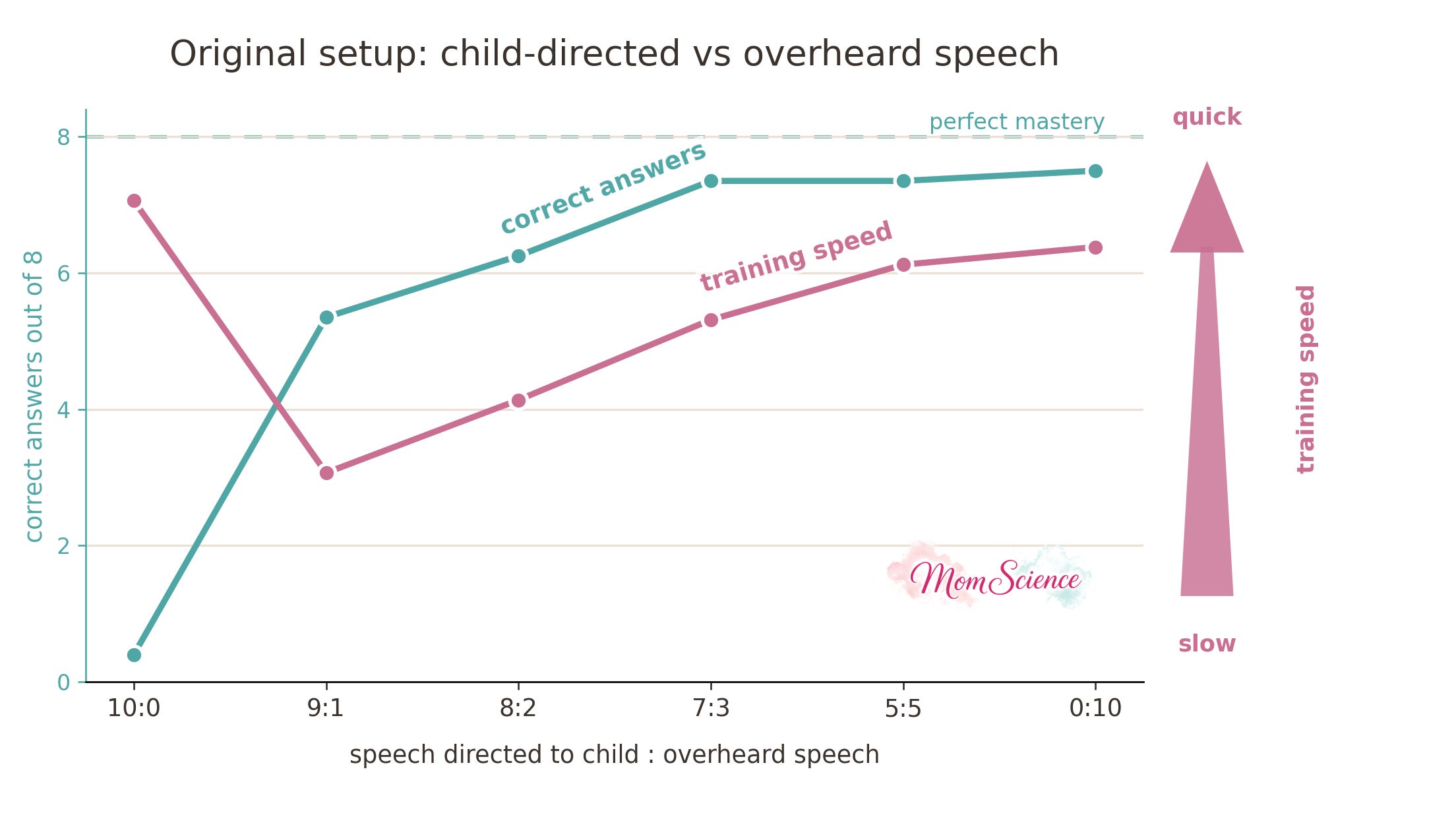
We measure mastery as a score out of 8 since in the five-person setup, the child has eight different speaking scenarios where they have to pick the correct first- or second-person pronoun. Indeed, there are four people to talk to, and they either talk about themselves or the other person. That’s eight cases altogether.
While the task we are modeling is about speech, the model learns numbers. Every person in the model is assigned a value (child = 0, Mom = -2, …), and so are the first- and second-person pronouns (“I” = +0.5 and “you” = -0.5).
If you have a background in modern machine learning, your instinct might be to one-hot encode these distinct categories. However, the authors of the 1999 paper made this scalar choice intentionally: by mapping everyone along a continuous scale, they baked the concept of shared “personhood” right into the network. By putting the parents and the child on the same numerical scale, the simulation captures that the child recognizes: “Mom and Dad are people, and so am I”.
Each situation is then translated to a vector of three numbers: who is speaking, who they are talking to, and who they are talking about. In the training phase, the model gets the correct output as well. In the testing phase, the model is asked to produce that output. The outcome it gives is coming from a surface. It is not a binary “I” or “you”, but a number that is decoded as “I” above 0.4, “you” below -0.4, and is considered not confident in between. Just like a child who is unwilling to speak either version due to uncertainty.
Here are the surfaces I got after a randomly chosen training session for a couple of scenarios:
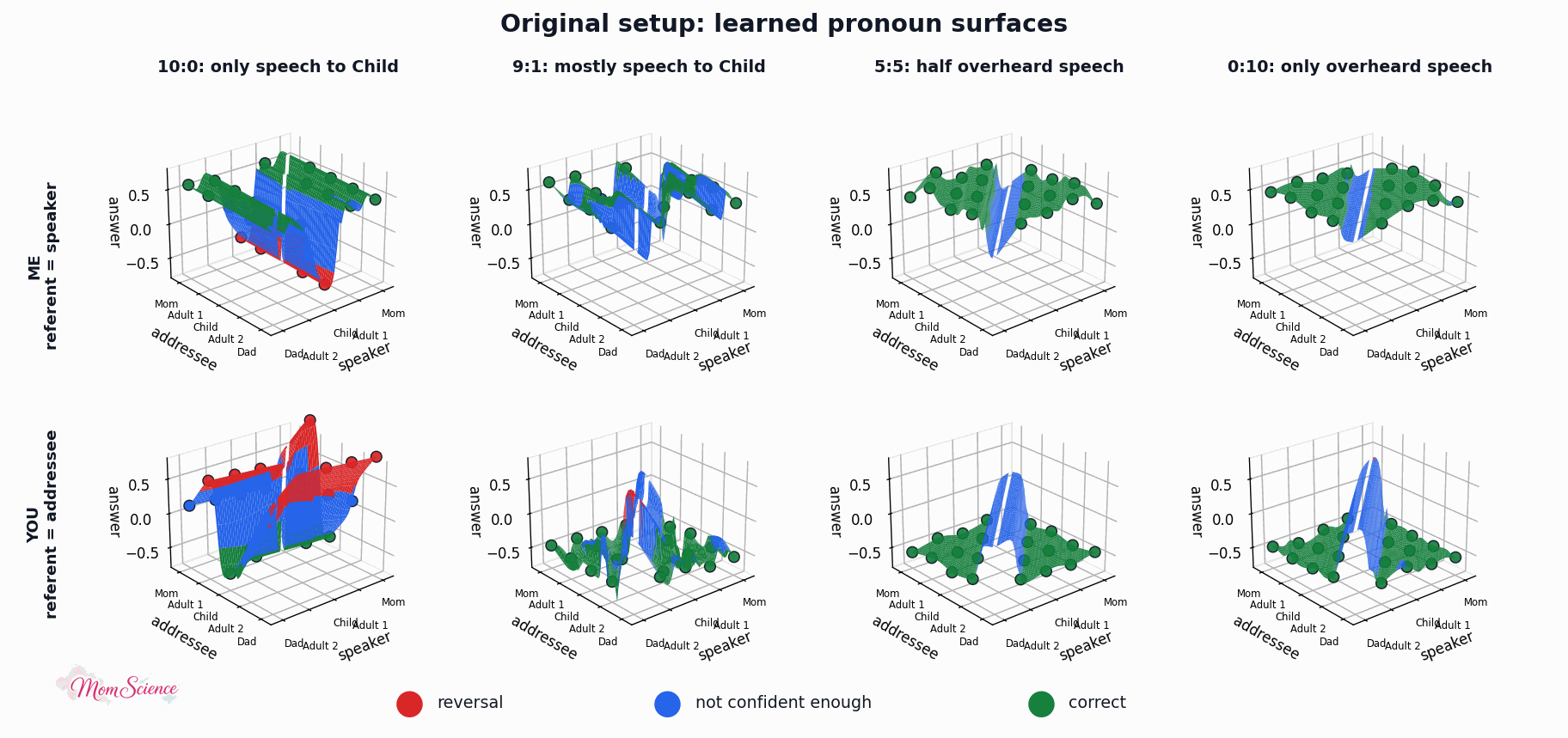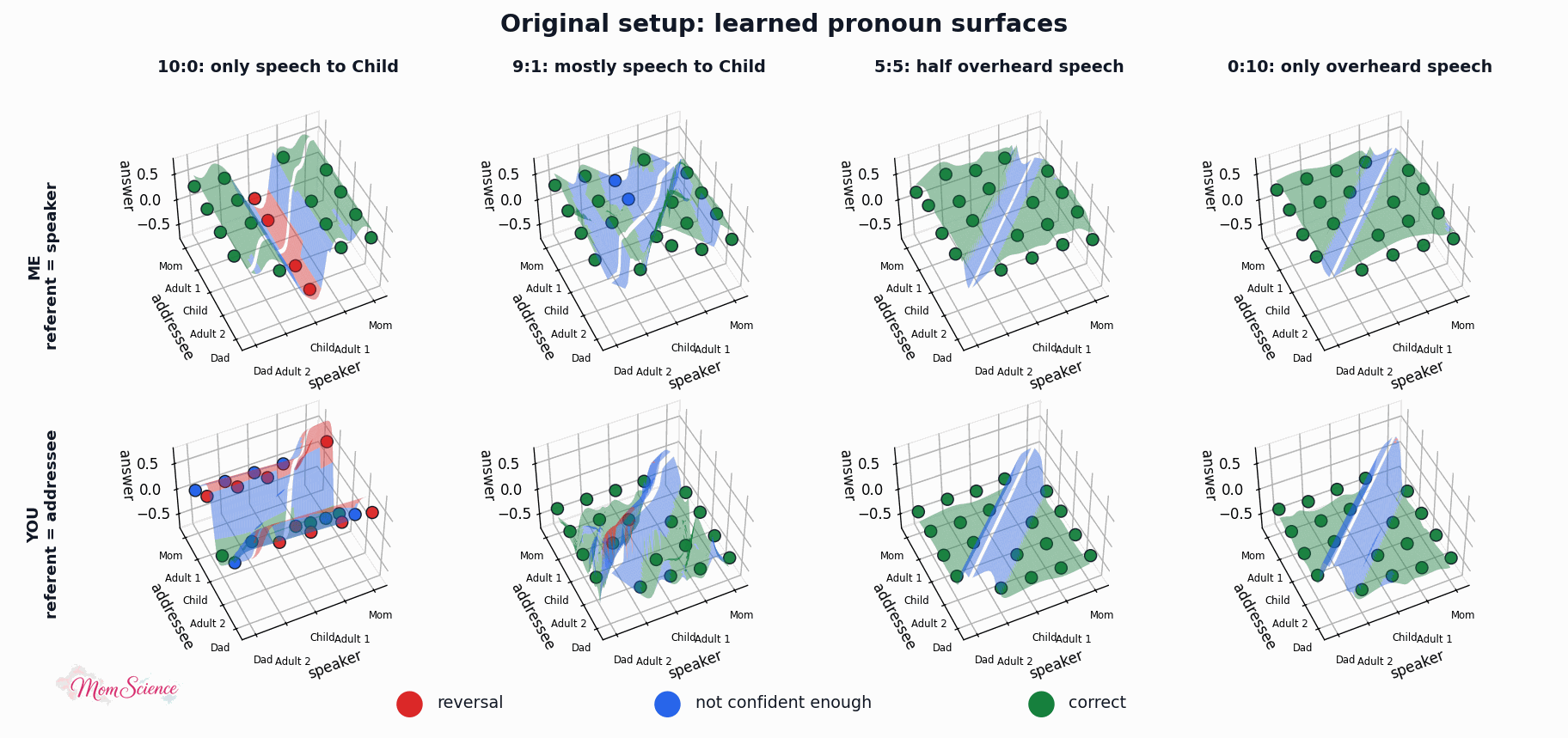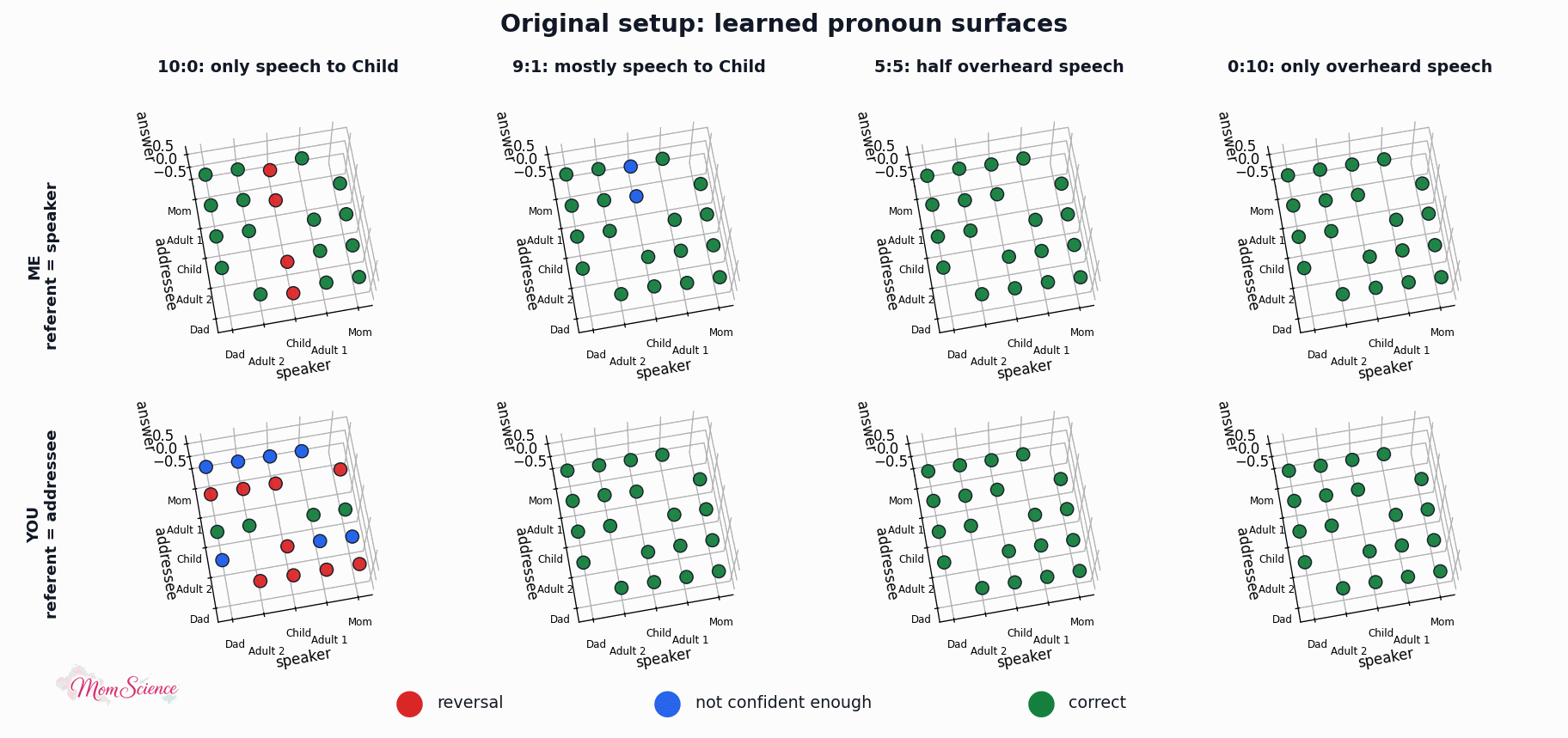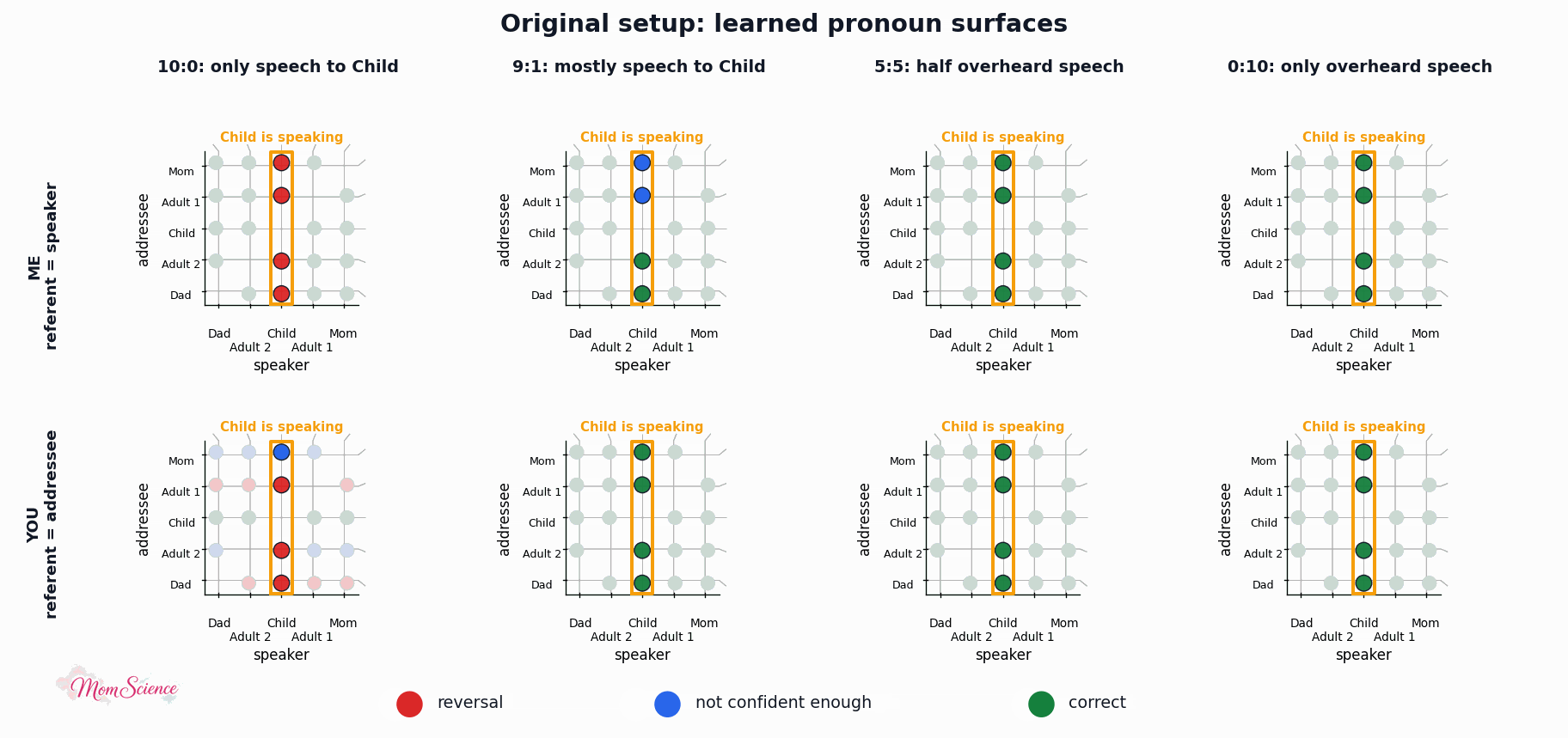
My model is not the exact same as in the simulation paper, and the results are not matching perfectly either. In that paper, they had a clean cut: it was all wrong until overheard speech got to 20%, and all perfect afterwards. My results are softer; we see a gradual increase in mastery. (Which, to be honest, I find more true to real life.) However, the overall pattern is captured nicely, so I was confident to move on to the next stage: adding absolute labels to the model.
The Simulation Study About Absolute Labels — Continue Reading Here
To simulate the effect of adding absolute labels to the speech that children hear, first of all, I had to pick a linguistic environment for the child. I decided to stick to the one with 10% overheard and 90% child-directed speech for two separate reasons:
As we saw previously, in the original simulation setup, that is where the neural network took the longest to train and had a great challenge mastering the first- and second-person pronouns. So it made sense to try and boost the learning here, where there is room to improve and a reasonable chance to do so.
In the simulation paper, the 10% overheard speech environment was compared to that of a first-born child, while the 50-50 case was linked to a second- or later-born sibling. Since the Smiley study focused on first-born children, the 9:1 case aligns well.
Now on to the addition of absolute labels! The Smiley study treated them separately for the parent and the child and called each case high if these alternative references were used in at least 10% of the relevant situations. This way, for the 11 children, they ended up with three groups: two kids in the low-low setting; seven in high-low, where the parents often used absolute labels for themselves, but almost always referred to the child as “you” when talking to them; and two in the high-high setting. I will add these three setups to the original simulation.
“At least 10%” is too loose for me to set the simulation up, but the Smiley paper included a detailed table of the actual percentages for the 11 children, based on which I decided to use
5% as the low setting;
40% for parental absolute labels in high setting;
yet only 15% for the counterpart about the child in the high setting.
To introduce absolute labels in the child-directed speech, I added stable anchors to the desired percentage of the training data. I didn’t replace “I’m here” with “Mommy’s here”; it became “I’m here. Mommy’s here” instead. (In the form of numbers, this meant an additional value to indicate that there is an additional absolute label accompanying the pronoun. The output didn’t change.)
When I first ran the three setups (low-low, high-low, high-high) in this 10% overheard speech scenario, I was surprised to see that high-low and high-high were leading head-to-head. Which is a bummer since high-high was supposed to take the lead.
However, I quickly realized what went wrong! The Smiley study shed light on an important phenomenon: child-directed speech is mostly about the child, not the adult. Indeed, they are the subject of these sentences almost five times more than the adults, which really does make sense.
Do you see the issue now? On my first try, I used the absolute label percentages on the training data, where half of the child-directed speech was talking about the adult, the other half about the child. Meanwhile, based on the Smiley paper, the subject should be the adult in only 18% of the sentences, and the child in 82%, which is a big difference! And not just in who is the subject of the majority of the speech, but also the final number of absolute labels for the adult and the child. Take a look at this plot:
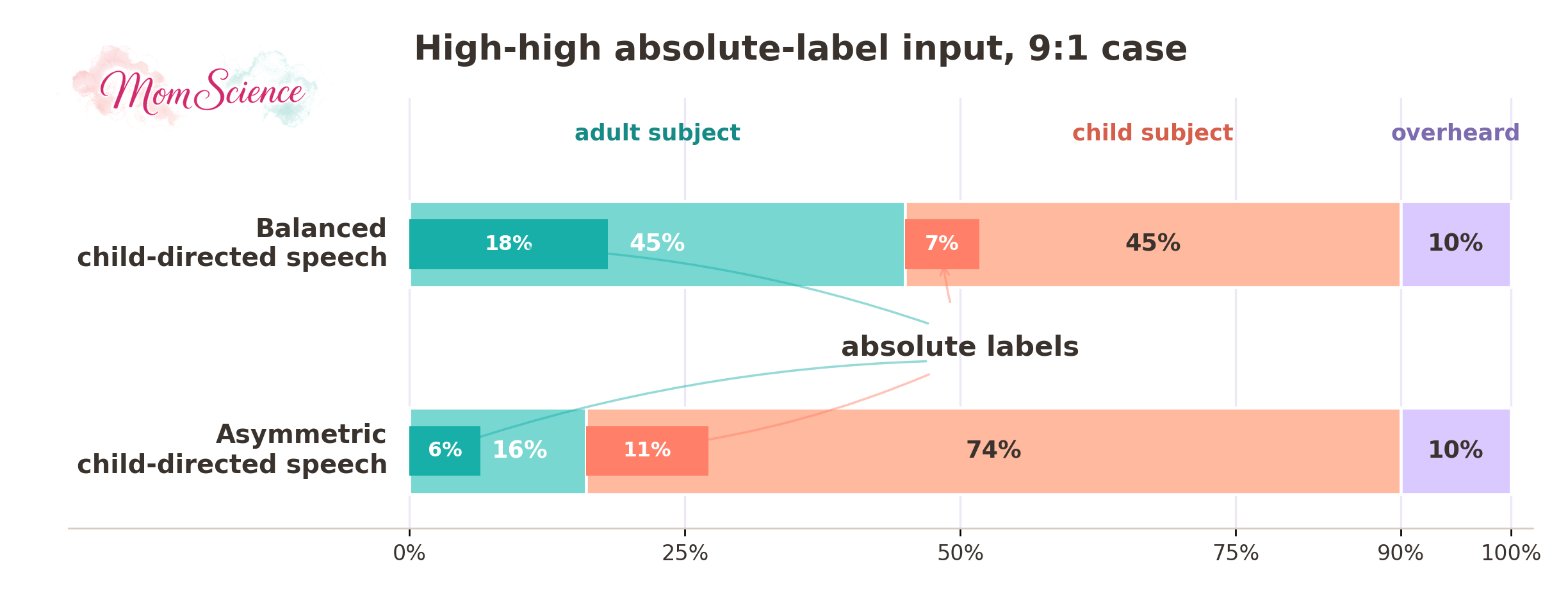
In the balanced case, there were more than twice as many absolute labels for the adults than for the child, while it should have really been the other way around.
So, to fit the 11 children in the Smiley-study better, I adjusted the training data such that 82% of the child-directed speech had the child as the subject. Then I re-ran the scenarios. This time, I did see that high-high performed the best out of all. It was the fastest to learn and used the most correct pronouns:
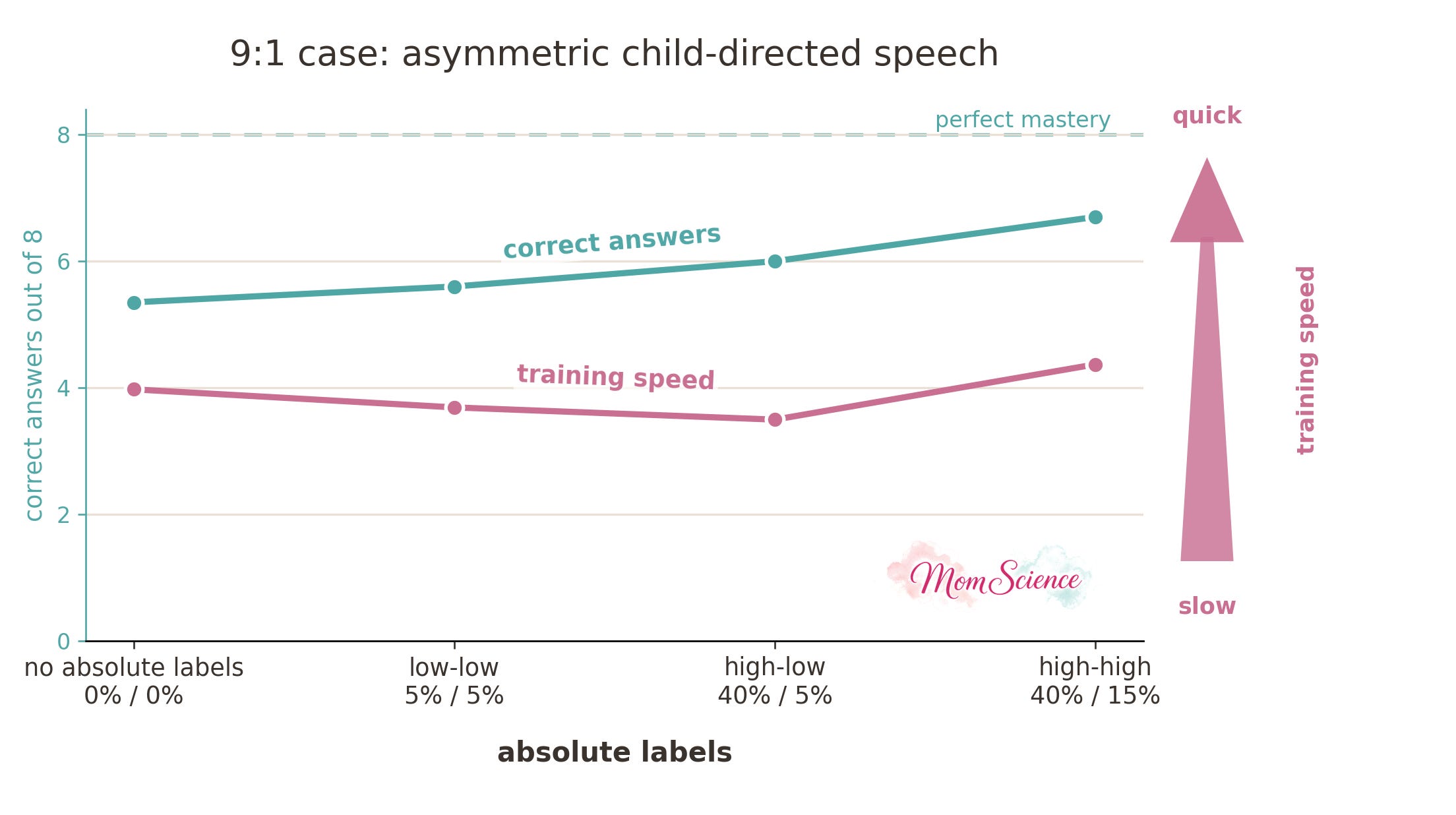
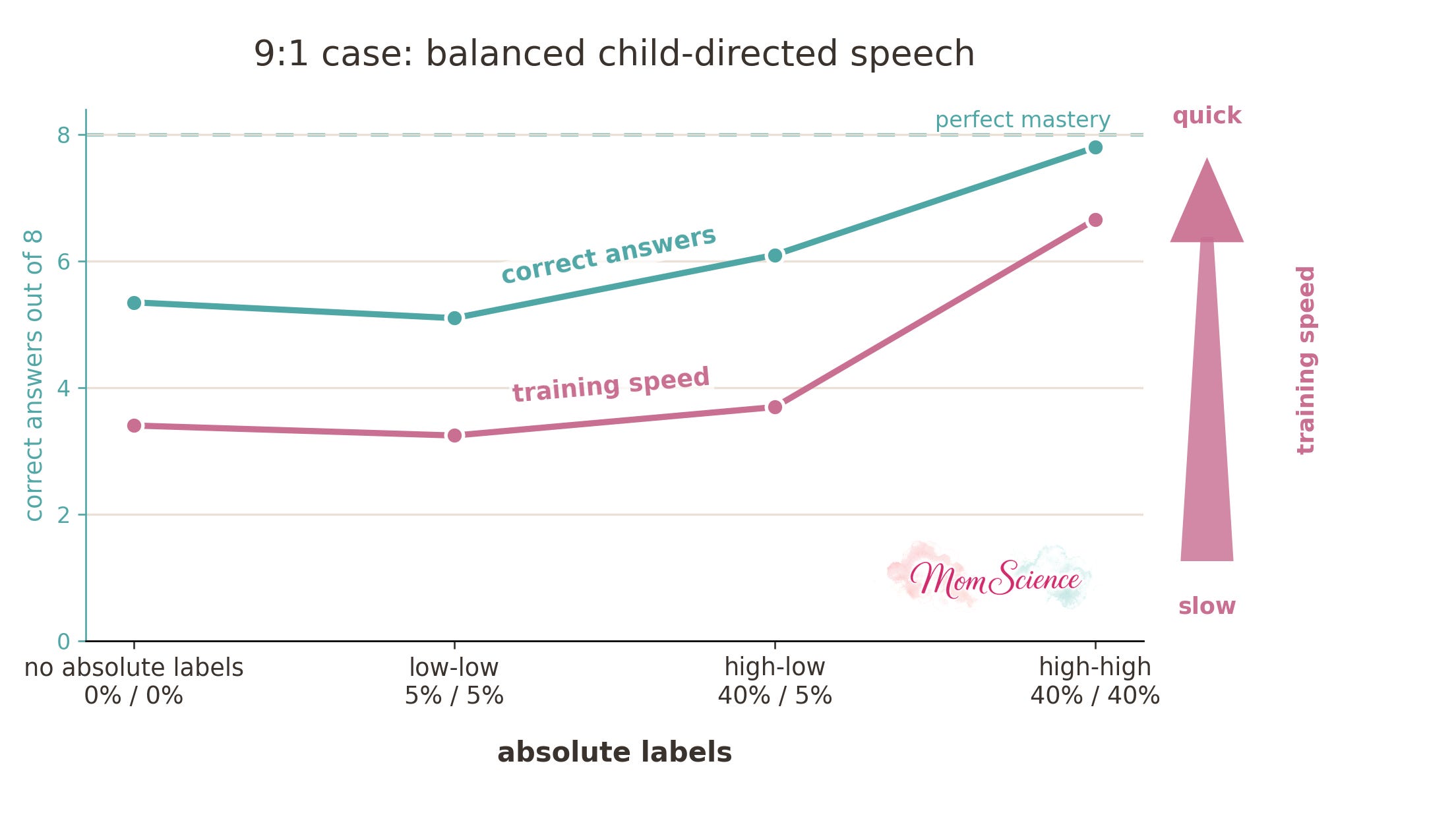
Just to make sure that the effect is not specific to this particular linguistic environment, I also tried the original balanced version where I balanced the absolute label uses as well: 40% for both the adults and the child. This version shows an even larger benefit for the high-high case than the asymmetric version did:
Let me show you one final plot, the associated surfaces. You can see what the absolute labels did: they solidified the remaining unconfident outputs.
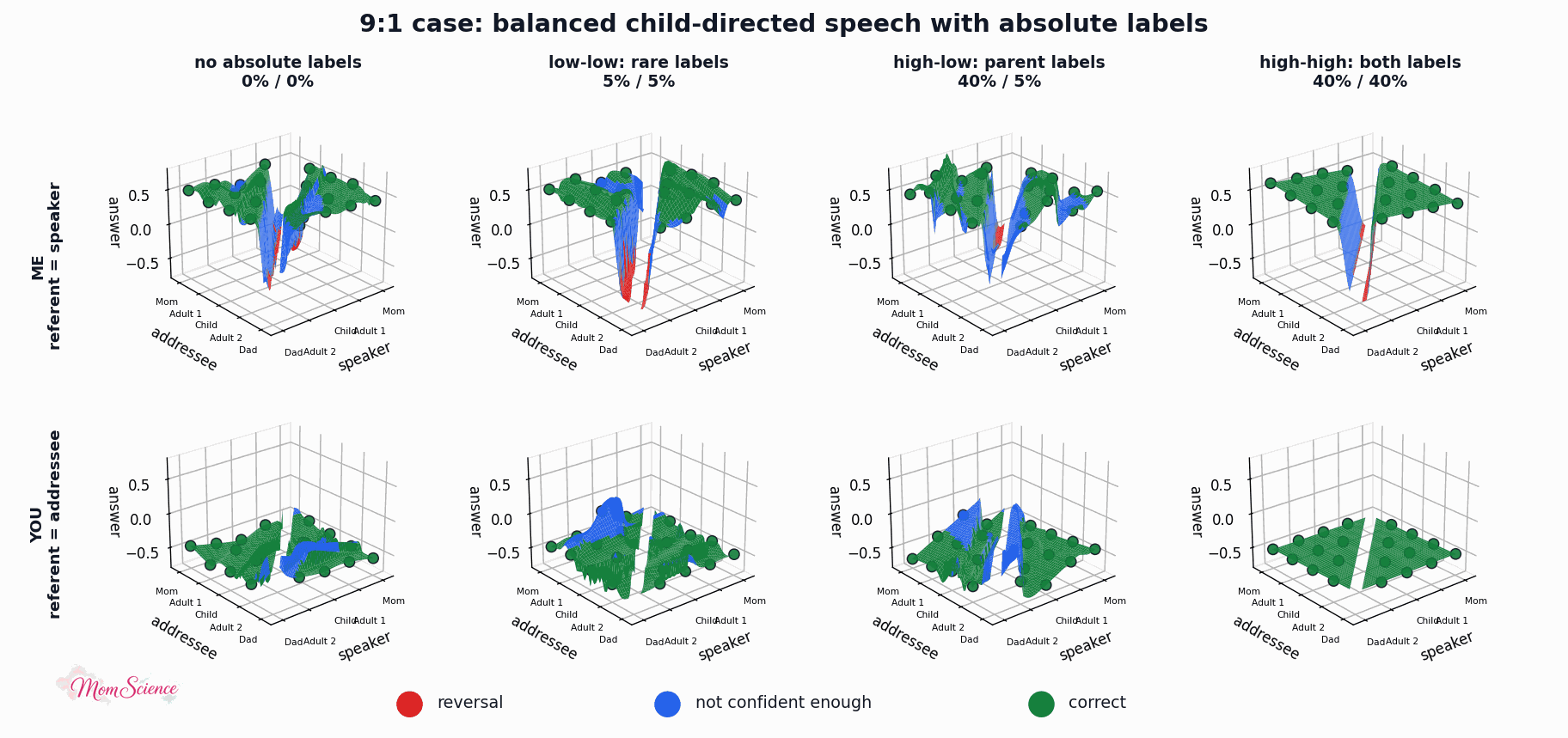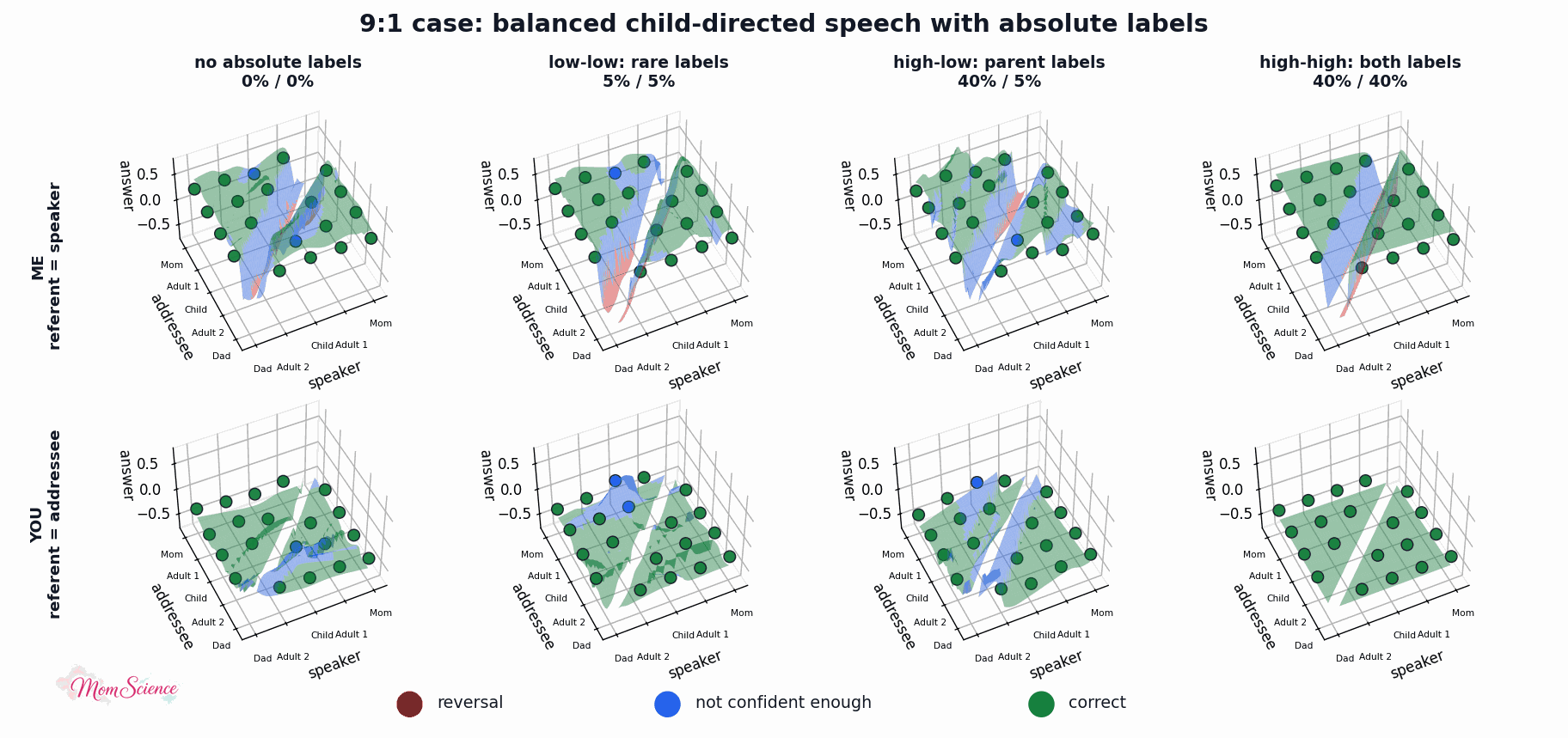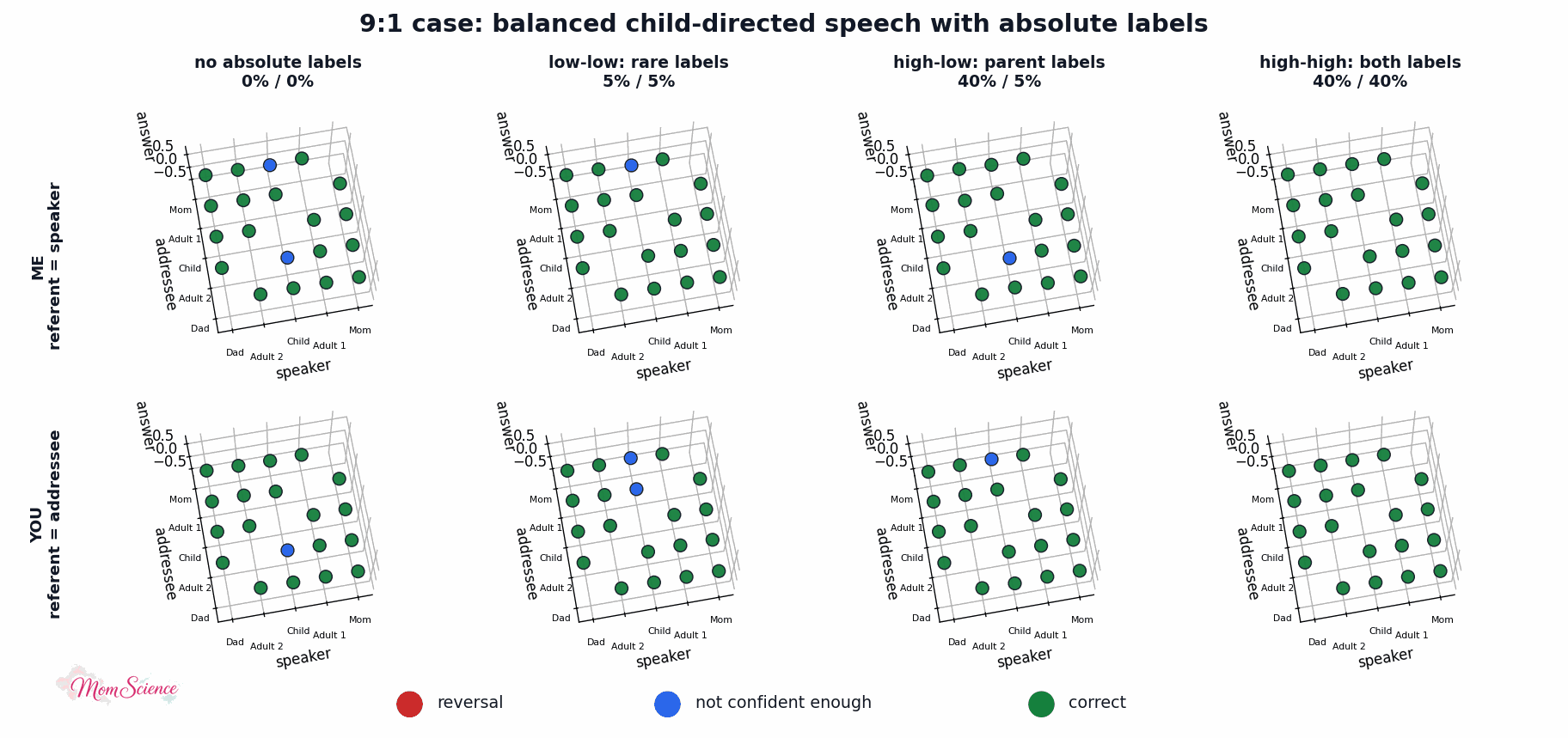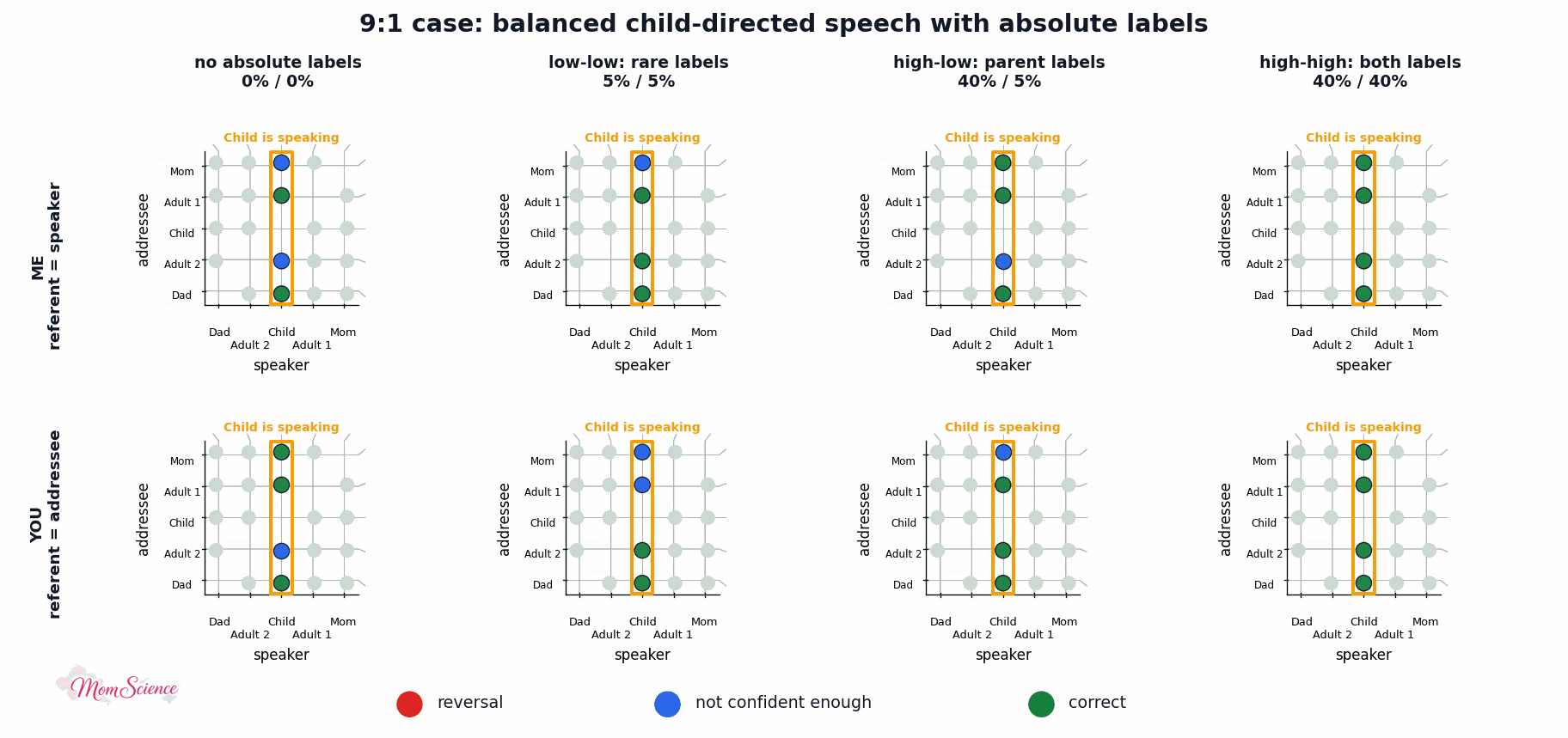
Still not proof that referring to myself as Mommy when I talk to my child, or referring to them by their name or the term “baby”, helps them master the pronouns “I” and “you”. However, I’ll at least take this as a mild reassurance that I am not causing harm when I talk to the baby this way.
So the next time you are annoyed at yourself for talking about yourself as “Mommy”, remember that even if the related study lacks a large sample, it supports your parental instinct. And my simulation backed this up!
Just make sure you drop the habit by the time your kid goes to college.
The Summary
First- and second-person pronouns are hard for children to learn because of their shifting nature: “I” does not always refer to the same person, but to the one currently in the speaking role.
Calling ourselves “Mommy” when talking to our young child, or calling them by their real name instead of “you” (aka. absolute labels) provide anchors in the sea of shifting pronouns to the child.
A study followed the pronoun learning process of 11 first-born children and found that the two who were exposed to plenty of absolute labels in addition to the correct pronouns learned to use the first- and second-person pronouns more easily. But the study sample is too small!
I trained a Cascade-Correlation neural network to learn first- and second-person pronouns in different setups: no, little, or plenty of absolute labels for the adult and the child. The latter was the most successful, which supports the idea that the habit of saying things like “Mommy loves you” could be useful.
Smiley, P. A., Chang, L. K., & Allhoff, A. K. (2011). Can Toddy give me an orange? Parent input and young children’s production of I and you. Language Learning and Development, 7(2), 77–106. https://doi.org/10.1080/15475441.2010.499495
Oshima-Takane, Y., Takane, Y., & Shultz, T. R. (1999). The learning of first and second person pronouns in English: Network models and analysis. Journal of Child Language, 26(3), 545–575. https://doi.org/10.1017/S0305000999003906